Over the decades, information technology has been improving business processes drastically and has become a strategic solution for enterprises worldwide. What was once a “nice-to-have” is now a must-have. Applications are the core of any business and over recent years, their use has been augmented drastically. Therefore, the response time has become even more significant. Data retrieval time plays a key role in user experience and is a critical requirement in almost all commercial applications. There are various factors affecting response time today, including network pipes, protocols, hardware, software, and internet speed. Vast IT infrastructure and ever-demanding system performance seriously undermine the strategic goals of any organization.
The goal of this article is to highlight a Java caching mechanism to improve application performance.
Concept of the Cache
A cache is a memory buffer used to temporarily store frequently accessed data. It improves performance since data does not have to be retrieved again from the original source. Caching is actually a concept that has been applied in various areas of the computer/networking industry for quite some time, so there are different ways of implementing cache depending upon the use case. In fact, devices such as routers, switches, and PCs use caching to speed up memory access. Another very common cache, used on almost all PCs, is the web browser cache for storing requested objects so that the same data doesn’t need to be retrieved multiple times. In a distributed JEE application, the client/server side cache plays a significant role in improving application performance. The client-side cache is used to temporarily store the static data transmitted over the network from the server to avoid unnecessarily calling to the server. On the other hand, the server-side cache is used to store data in memory fetched from other resources.
The cache can be designed on single/multiple JVM or clustered environment. Different scalability scenarios where caching can be used to meet the nonfunctional requirement are as follows.
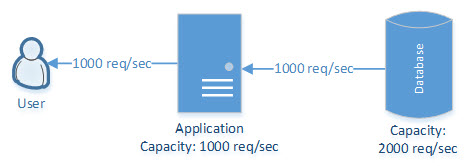
Vertical Scalability
This can be achieved by upgrading a single machine with more efficient resources (CPU, RAM, HDD, and SSD) and implementing caching. But it has limitations in regards to upgrading a cache up to a certain limit. In the below use case, the application’s performance can be enhanced by adding more memory and implementing caching at the application level.
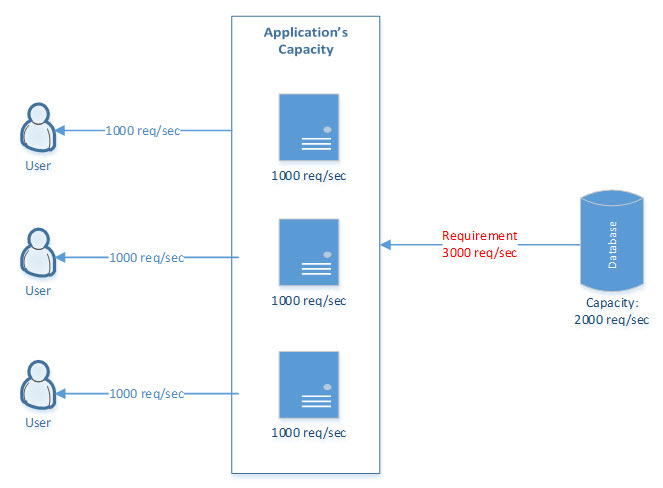
Horizontal Scalability
This can be achieved by adding more machines and implementing caching at the application level on each machine. But is still has limitations in regards to communicating with downstream applications where additional servers cannot be added. In the below use case, the overall application’s performance can be enhanced by adding a server/cache per application. The database has some limitations in regards to fulfilling this requirement, but this can be mitigated by storing static/master data in a cache.
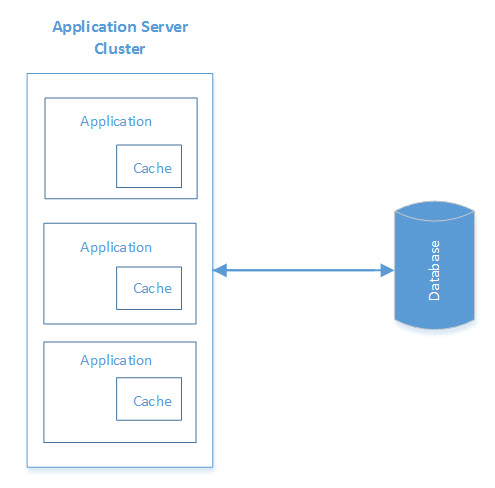
In-Process Caching
In-process caching enables objects to be stored in the same instance as the application, i.e. the cache is locally available to the application and shares the same memory space.
Here are some important points for considering in-process caching:
- If the application is deployed only in one node, i.e. has a single instance, then in-process caching is the right candidate to store frequently accessed data with fast data access.
- If the in-process cache will be deployed in multiple instances of the application, then keeping data in sync across all instances could be a challenge and cause data inconsistency.
- If server configurations are limited, then this type of cache can degrade the performance of any application since it shares the same memory and CPU. A garbage collector will be invoked often to clean up objects that may lead to performance overhead. If data eviction isn’t managed effectively, then out-of-memory errors can occur.
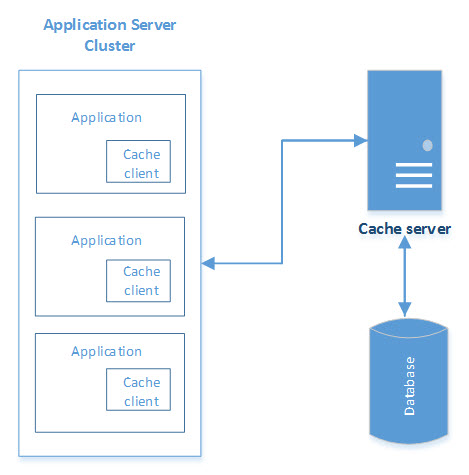
In-Memory Distributed Caching
Distributed caches (key/value objects) can be built externally to an application that supports read/write to/from data repositories, keeps frequently accessed data in RAM, and avoid continuous fetching data from the data source. Such caches can be deployed on a cluster of multiple nodes, forming a single logical view. Caching clients use hashing algorithms to determine the location of an object in a cluster node.
Here are some important points for considering distributed caching:
- An in-memory distributed cache is the best approach for mid- to large-sized applications with multiple instances on a cluster where performance is key. Data inconsistency and shared memory aren’t matters of concern, as a distributed cache is deployed in the cluster as a single logical state.
- As inter-process is required to access caches over a network, latency, failure, and object serialization are some overheads that could degrade performance.
- Its implementation is more difficult than in-process caching.
In-Memory Database
This type of database is also called a main memory database. It’s where data is stored in RAM instead of a hard disk to enable faster responses. Data is stored in compressed format with good SQL support. Relevant database drivers can be used in place of an existing RDBMS.
Replacing the RDBMS with an in-memory database will improve the performance of an application without changing the application layer. Only vertical scaling is possible for scaling up the in-memory database.
In-Memory Data Grid
This distributed cache solution provides fast access to frequently used data. Data can be cached, replicated, and partitioned across multiple nodes.
Implementing the in-memory data grid will improve the performance of and scale an application without changing the RDBMS.
Key features include:
- Parallel computation of the data in memory
- Search, aggregation, and sorting of the data in memory
- Transactions management in memory
- Event-handling
Cache Use Cases
There are use cases where a cache is used to improve application performance via various commercial/open-source cache frameworks that can be configured in any enterprise application. Here are common cache use cases.
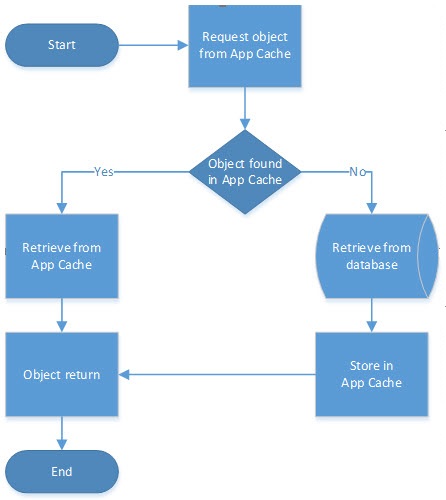
Application Cache
An application cache is a local cache that an application uses to keep frequently accessed data in memory. An application cache evicts entries automatically to maintain its memory footprint.
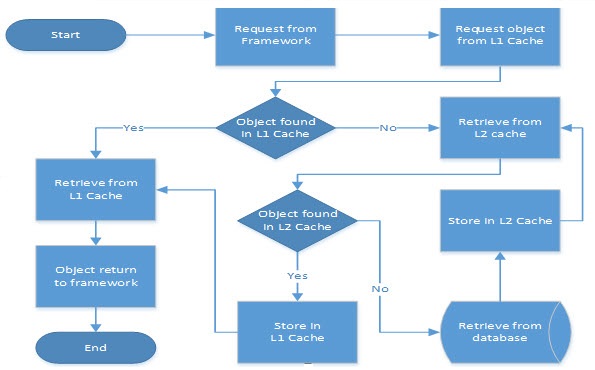
Level 1 (L1) Cache
This is the default transactional cache per session. It can be managed by any Java persistence framework (JPA) or object-relational mapping (ORM) tool.
The L1 cache stores entities object that fall under a specific session and is cleared once a session is closed. If there are multiple transactions inside one session, all entities will be stored from all these transactions.
Level 2 (L2) Cache
The L2 cache can be configured to provide custom caches that can hold onto the data for all entities to be cached. It can be related to properties, associations, and collections. It’s configured at session factory-level and exists as long as the session factory is available.
The L2 cache can be configured to be available across:
- Sessions in an application.
- Applications on the same servers with the same database.
- Clusters for different applications on different servers on the same database.
Usages of an L1/L2 cache, if the L2 is configured:
- The standard ORM framework first looks up an entity in the L1 cache, and then the L2 cache. The L1 cache is the initial search space to look up entities. If the cached copy of an entity is found, then it is returned.
- If no cached entity is found in the L1 cache, then it’s looked up in the L2 cache.
- If a cached entity is found in the L2 cache, then it’s stored in the L1 cache and then returned.
- If an entity is not found in L1 nor L2, then it’s fetched from the database and stored in both caches before returning to the caller.
- L2 cache validates/refreshes itself when any modification happens on entities by any session.
- If the database is modified at all by external processes, i.e. without application session, then the L2 cache cannot be refreshed implicitly until some cache refresh policy is implemented either through the framework API or some custom API.
The following communication diagram illustrates using an L1/L2 cache:
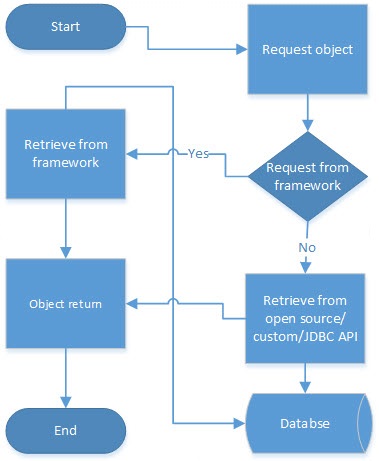
Hybrid Cache
A hybrid cache is a combination of a cache provided by standard ORM framework and open-source/custom/JDBC API implementations. An application can use a hybrid cache to leverage cache capability that’s limited to standard ORM framework. This kind of cache is used in mission-critical applications where response time is significant.
Caching Design Considerations
Caching design considerations include data loading/updating, performance/memory size, eviction policy, concurrency, and cache statistics.
Data Loading/Updating
Data loading into a cache is an important design decision to maintain consistency across all cached content. The following approaches can be considered to load data:
- Using default function/configuration provided by standard ORM framework, i.e. Hibernate or OpenJPA.
- Implementing key-value maps using open-source cache APIs, i.e. Google Guava or COTS products like Coherence, Ehcache, or Hazelcast.
- Programmatically loading entities through automatic or explicit insertion.
- External application through synchronous or asynchronous communication.
Performance/Memory Size 32/64 Bit
Available memory is an important factor to achieve performance SLA and it depends on 32/64 bit JRE, which is further dependent on 32/64-bit CPU architecture machines. In a 32-bit system/JRE, ~1.5 GB of heap is left for application use, while in a 64-bit system/JRE, heap size is dependent on RAM size.
High availability of memory does have cost at runtime and can have negative consequences.
- 30-50% more heap is required on 64-bit compared to 32-bit due to memory layout.
- Maintaining more heap requires more GC work for cleaning unused objects that can degrade performance. Fine-tuning GC can be an option to limit GC pauses.
Eviction Policy
An eviction policy enables a cache to ensure that the size of the cache doesn’t exceed the maximum limit. To achieve this, existing elements are removed from a cache depending on the eviction policy, but it can be customized as per application requirements. There are various popular eviction algorithms used in cache solution:
- Least Recently Used (LRU)
- Least Frequently Used (LFU)
- First In, First Out (FIFO)
Concurrency
Concurrency is a common issue in enterprise applications. It creates conflict and leaves the system in an inconsistent state. It can happen when multiple clients try to update the same data object at the same time during cache refresh. A common solution is to use a lock, but this may affect performance. Hence, optimization techniques should be considered.
Cache Statistics
Cache stats help identify the health of the cache and provide information about cache behavior and performance. In general, the following attributes can be used in cache statistics:
- Hit count: Number of look-ups encountered when object found
- Miss count: Number of look-ups encountered when object not found
- Load success count: Number of successfully loaded entries
- Total load time: Total time in loading an element
- Load exception count: Number of exceptions thrown while loading an entry
- Eviction count: Number of entries evicted from the cache
Summary: Various Cache Solutions
There are various Java caching solutions available — the right choice for you depends on your use case. Here are some questions and comparisons that can assist in identifying the most cost-effective and feasible caching solution for you.
- Do you need a light-weighted or full-fledged cache solution?
- Do you need an open-source, commercial, or framework-provided cache solution?
- Do you need in-process or distributed caching?
- What’s the trade-off between consistency and latency requirements?
- Do you need to maintain the cache for transactional/master data?
- Do you need a replicated cache?
- What about performance, reliability, scalability, and availability?